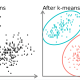
K-Means Clustering dalam analisis data Digital Marketing

Dalam dunia digital marketing, Anda dapat menerima umpan balik tentang bagaimana interaksi ataupun engagement audiens Anda hingga ke level individu, baik melalui click tracking, pembelian online, sharing, dan seterusnya. Data ini adalah gambaran dari audiens Anda.
Pertanyaannya, bagaimana Anda dapat mengambil sekumpulan data transaksi atau interaksi dari audiens Anda itu (atau pengguna, pelanggan, warga negara, dan sebagainya) dan menggunakannya untuk dapat lebih memahami mereka? Ketika berurusan dengan orang dalam jumlah besar, pasti sulit untuk memahami setiap pelanggan secara personal, terutama jika mereka memiliki cara yang berbeda-beda dalam berinteraksi dengan kampanye digital Anda. Bahkan jika Anda bisa memahami setiap pelanggan secara personal pun, Anda harus memikirkan strategi yang efisien dalam menjangkau atau memenuhi keinginan setiap orang ini.
Nah untuk itu, Anda harus menemukan jalan tengah yang tepat antara menjangkau sebanyak-banyaknya orang dengan kampanye Anda (seolah-olah mereka adalah entitas tak berwajah yang semuanya sama) atau memahami setiap orang untuk membuat kampanye pemasaran yang sesuai dengan kebutuhan dan keinginan setiap orang ini (targeted campaign).
Salah satu cara mencapai keseimbangan tersebut adalah dengan menggunakan pengelompokan (clustering) untuk membuat segmentasi pasar, sehingga Anda dapat membuat kampanye pemasaran ke segmen-segmen tersebut dengan konten yang telah ditargetkan (disesuaikan dengan karakteristik masing-masing segmen).
Cluster Analysis adalah praktik mengumpulkan sejumlah objek dan memisahkannya menjadi beberapa kelompok yang serupa. Dengan menganalisis kelompok-kelompok ini, Anda dapat menentukan kemiripan dan perbedaannya. Anda dapat mempelajari banyak hal tentang pola data acak yang Anda miliki ini. Wawasan tersebut dapat membantu Anda membuat keputusan yang lebih baik pada tingkat yang lebih detail.
K-Means Clustering
Salah satu algoritma clustering yang paling sederhana dan populer adalah K-Means Clustering. Tujuan dari algoritma ini adalah untuk menemukan grup dalam data, dengan jumlah grup yang diwakili oleh variabel K. Variabel K sendiri adalah jumlah cluster yang kita inginkan.
Untuk memproses data algoritma K-means Clustering, data dimulai dengan kelompok pertama yang dipilih secara acak, yang digunakan sebagai titik awal untuk setiap cluster, dan kemudian menghitung perhitungan berulang (berulang) untuk mengoptimalkan fungsi centroid.
Proses ini berhenti atau telah selesai dalam mengoptimalkan cluster ketika:
- Centroid telah stabil – tidak ada perubahan dalam nilai-nilai mereka karena pengelompokan telah berhasil.
- Jumlah iterasi yang ditentukan telah tercapai.
Adapun tahapan algoritma ini adalah sebagai berikut :
- Pertama, tentukan berapa banyak jumlah k (cluster)
- Kedua, secara acak tentukan record yang menjadi lokasi pusat cluster.
- Ketiga, temukan pusat cluster terdekat untuk setiap record. Adapun persamaan yang sering digunakan dalam pemecahan masalah dalam menentukan jarak terdekat adalah persamaan Euclidean berikut :
Dimana x=x1,x2,x3……xm dan y=y1,y2,y3…ym, sementara m menyatakan banyaknya nilai atribut dari 2 buah record.
- Keempat, tentukan cluster terdekat untk setiap data dengan membandingkan nilai jarak terdekat, lalu perbaharui nilai pusat cluster-nya
- Kelima, ulangi langkah 3 sampai 5 hingga tidak ada record yang berpindah cluster atau convergen.
Contoh Sederhana
Berikut terdapat 8 record yang akan menjadi dataset kemudian dataset tersebut akan kita gunakan dalam membantu memahami penerapan algoritma k-means clustering.
Langkah Pertama, tentukan jumlah cluster, sebagai contoh jumlah cluster yang akan di bentuk dari dataset di atas adalah 2 Cluster (kelompok).
Langkah Kedua, tetapkan 2 record dari dataset sebagai titik pusat cluster.
M1 : {1,1} -> Titik pusat Cluster pertama (C1)
M2 : {2,1} -> Titik pusat Cluster kedua (C2)
Langkah ketiga, tentukan pusat cluster terdekat untuk setiap record dari dataset
Nah, untuk tahap ini kita akan menggunakan persamaan Euclidean untuk menentukan jarak setiap record dengan pusat cluster.
Dan dihitung seterusnya hingga data paling akhir (data ke 8), sehingga diperoleh rekap hasil perhitungan jarak terdekat ke setiap cluster sebagai berikut :
Langkah Keempat, tentukan cluster (kelompok) setiap record dan perbaharui titik pusat cluster.
Setelah cluster (kelompok) untuk setiap record ditentukan seperti pada tabel di atas, tugas kita sekarang adalah memperbaharui nilai titik pusat cluster, yang mana sebelumnya titik pusat cluster kita adalah M1{1,1} dan M2{2,1}. Untuk meng-update nilai titik pusat cluster, kita dapat menggunakan persamaan cluster center sebagai berikut :
Maka titik pusat cluster terbaru adalah sebagai berikut :
Adapun hasil pengelompokan setelah melakukan ulang langkah 3 dan langkah 4 adalah sebagai berikut :
Pada iterasi 2, tidak terjadi perpindahan kelompok pada setiap data, dengan ini maka pengelompokan sudah dinyatakan konvergen atau sudah dianggap optimal.
K-means bukanlah teknik clustering yang paling teliti secara matematis. Algoritma ini mewakili kepraktisan dan intuisi umum. Analisis cluster dengan k-means sering disebut separuh matematika, separuh story-telling. Namun kesederhanaannya secara intuisi itulah yang menjadi daya tarik dari algoritma ini.
Referensi :
https://www.wiley.com/en-id/Data+Smart%3A+Using+Data+Science+to+Transform+Information+into+Insight-p-9781118661468
https://www.alfasoleh.com/2019/11/k-means-clustering-contoh-sederhana.html